Machine Learning for Newbies(1): A Gentle Introduction
Introduction
As I embark on my learning journey to understand Large Language Models (LLMs), I have come to realize the importance of having a solid foundation in deep learning and Natural Language Processing (NLP).
To aid my own understanding and to potentially help others who may be similarly interested, I have created this note (or series of notes) to outline the basic concepts of deep learning and NLP. My goal is to provide a clear and concise introduction to these topics, using language that is accessible to those with a limited background in machine learning.
I hope that this note will serve as a helpful resource for anyone looking to gain a better understanding of the fundamental principles that underlie LLMs.
Note: This note is build on foundation that I have learned MATH447: Mathematics of Machine Learning, thus I will not dig deep into the math behind the models or basic concept of ML. If you are interested in the math behind the models, I strongly recommend you to take MATH447 or read the first few chapters of Understanding Machine Learning: From Theory to Algorithms by Shai Shalev-Shwartz and Shai Ben-David. And the structure of this notes is inspired by this post by Analytics Vidhya.
Basic Concepts
Neuron
Neurons are the fundamental building blocks of neural networks. Similar to how neuron function in human body, in a neural network, neurons process input and then output the results to other neurons or directly as the final output. 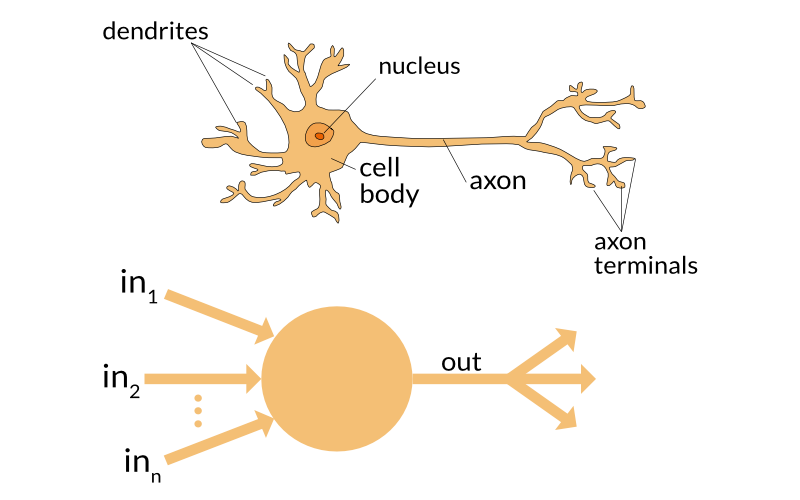
Weights
When an input signal enters a neuron, it is multiplied by a set of weights, which are also known as the weight factors. For example, if a neuron has two input signals, each input will have a corresponding weight factor. Initially, these weight factors are set randomly, and then they are adjusted continuously during the training process.
In a trained neural network, a higher weight factor for an input signal means that it is more important and has a greater impact on the output. On the other hand, if the weight factor is zero, it means that the input is worthless.
Suppose the input is a and the corresponding weight factor is W1. After the weighting process, the input becomes \(a*W1\).
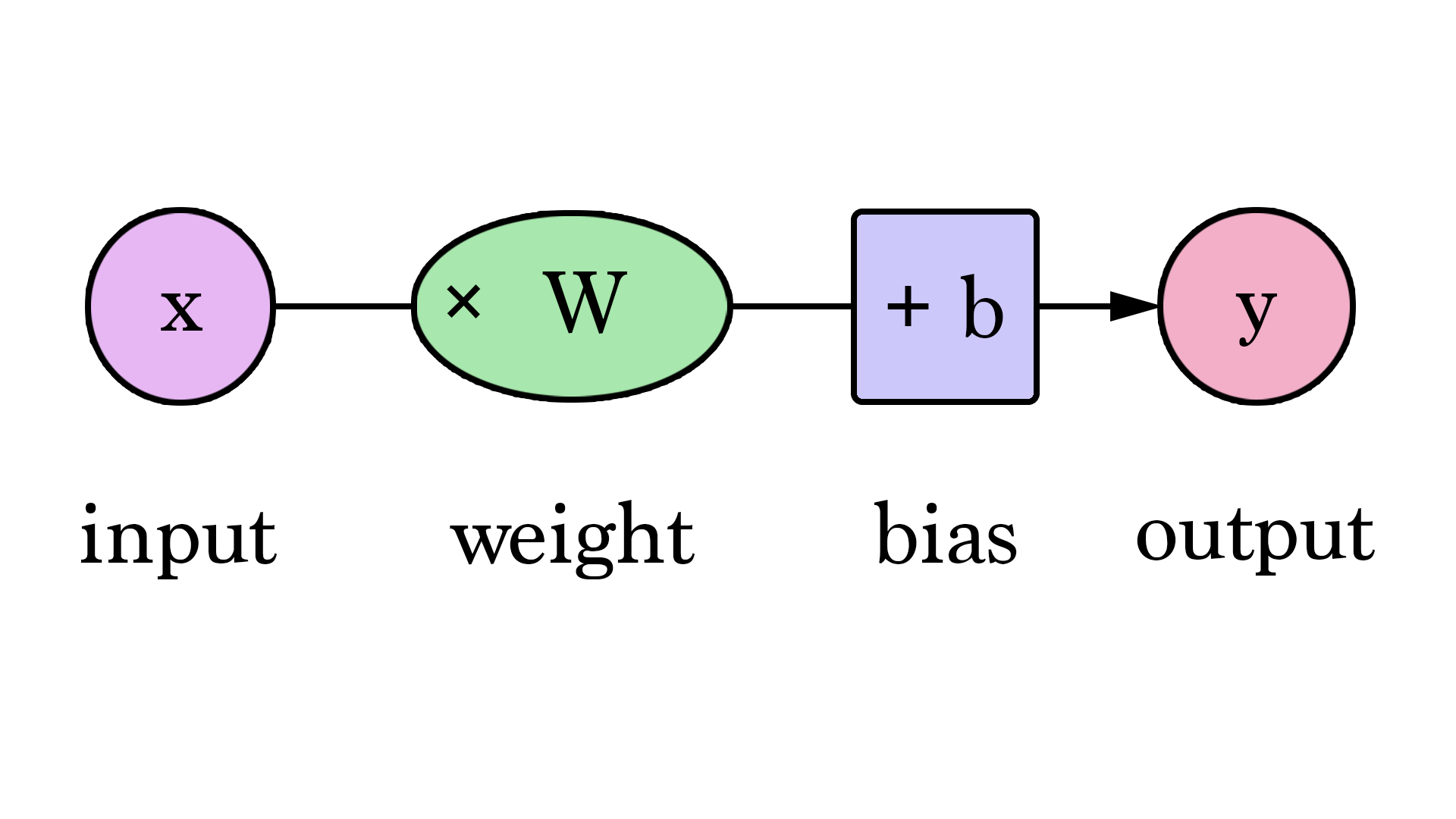
Bias
In addition to the weighting, the input also needs to go through another linear processing called bias. By adding the bias \(b\) to the weighted input signal \(a*W1\) directly, it becomes the input signal for the activation function.
Here's a step-by-step breakdown of the process:
- The input signal \(a\) enters the neuron.
- The weighting process is applied to the input signal a, resulting in a weighted signal \(a*W1\).
- The bias b is added to the weighted signal aW1, resulting in a new signal \(aW1 + b\).
- The new signal \(a*W1 + b\) is passed through an activation function (will be explained later), such as sigmoid or ReLU, to produce the output signal.
By incorporating the bias term, the neuron can learn to shift the activation function's output curve, allowing it to better model complex relationships between the inputs and outputs.
Activation Function
In the previous linear processing step, the input signal was transformed into a non-linear output signal through an activation function. The final output signal had the form \(f(a*W1+b)\), where \(f\) is the activation function.
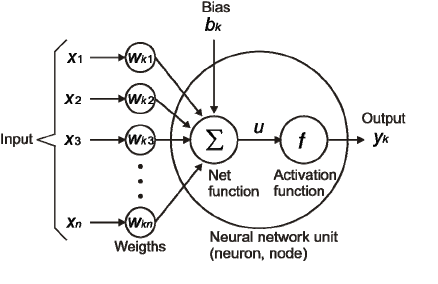
In the diagram below, the input \(X_1 \cdots X_n\) corresponds to the weight factors \(W_{k_1}...W_{k_n}\) and the biases \(b_1 \cdots b_n\). The output \(u\) is calculated by multiplying the input \(X_i\) by the corresponding weight factor \(W_{k_1}\) and adding the bias \(b_i\).
\[ u = \sum{w*x + b} \]
The activation function \(f\) operates on \(u\), producing the final output result \(y_k = f(u)\) for the neuron.